Wenn es um Klassifikation geht, dann sind binäre Klassifikationen die am weit verbreitetsten. Sie unterscheiden nur zwei Zustände. Entweder trifft eine Eigenschaft zu oder sie tut es nicht. Das klingt zwar sehr simpel, kann jedoch beliebig komplex werden. Beispielsweise sind Suchergebnisse das Resultat einer binären Klassifikation. Zu einem bestimmten Suchwort gibt entweder ein Match oder nicht. Das das ganze ziemlich einfach klingt, jedoch schwer umzusetzen ist zeigt die Vormachtstellung von Google im Bereich der Suchmaschinen.
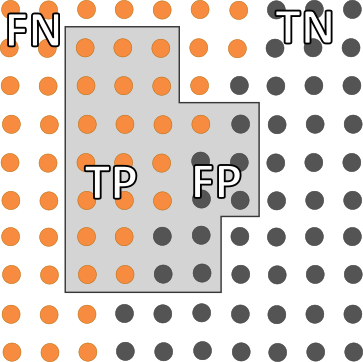
Die dargestellte Grafik zeigt die möglichen Fälle einer Klassifikation. Zum einen wird dabei zwischen positiven und negativen Ergebnissen unterschieden (orange und grau). Zum anderen wird zwischen erkannten und nicht erkannten Ergebnissen unterschieden (innerhalb und außerhalb der grauen Fläche).
- TP – Richtig positiv (true positive): Ein positives Ergebnis wurde richtig eingestuft.
- FP – Falsch positiv (false positive): Obwohl das Ergebnis negativ ist, wurde es fälschlicherweise als positiv eingestuft.
- TN – Richtig negativ (true negativ): Das Ergebnis ist negativ und wurde auch als negativ eingestuft.
- FN – Falsch negativ (false negativ): Ein positives Ergebnis wurde irrtümlich als negativ eingestuft.
Betrachten wir einen Klassifikator für blaue Blumen, welcher diese aus einer Sammlung von grünen und blauen Blumen erkennen soll. Ein richtig positives Ergebnis wäre es, wenn er eine blaue Blume als positiv erkennen würde. Ein falsch positives Ergebnis wäre eine grüne Blume, welche als blau erkannt wurde. Richtig negativ wäre eine grüne Blume welche nicht als blau erkannt wurde, wohingegen ein falsch negatives Ergebnis eine grüne Blume wäre, welche als blau erkannt worden wäre.
Wie in dem Beispiel mit den Blumen gibt es sehr oft Grenzfälle, die selbst ein Mensch nicht genau klassifizieren kann. Zwischen Grün und Blau einen fließenden Übergang. Wann ein Ergebnis richtig oder falsch ist kann von verschiedenen Menschen verschieden wahrgenommen werden.
Hat man nun einen Klassifikator entworfen, so möchte man diesen in den meisten Fällen auch bewerten können. Dazu gibt es eine Reihe von Kriterien, von den die wichtigsten die Sensitivität und die Genauigkeit sind.
Die Genauigkeit (Precision) sagt etwas darüber aus, wie viele der positiven Ergebnisse auch richtig Klassifiziert wurden. Hierfür betrachtet man das Verhältnis zwischen richtig positiv  und falsch positiven
und falsch positiven  Treffern.
Treffern.
(1) 
Umso größer die Genauigkeit, umso besser ist der Klassifikator. Bei der Sensitivität (recall) handelt es sich um das Verhältnis zwischen den positiv klassifizierten Treffern und den Ergebnissen, welche eigentlich positiv klassifiziert sein sollten  . Auch hier ist ein höherer Wert besser.
. Auch hier ist ein höherer Wert besser.
(2) 
Um eine Klassifikation beurteilen zu können müssen sowohl die falschen Treffer, wie auch die nicht getroffenen richtigen Ergebnisse betrachtet werden. Dazu eignet sich beispielsweise der  -Score. Wobei
-Score. Wobei  ein Parameter ist, welcher die Gewichtung zwischen Genauigkeit und Sensitivität festlegt. Klassifikatoren mit einer hohen Genauigkeit haben einen größeren
ein Parameter ist, welcher die Gewichtung zwischen Genauigkeit und Sensitivität festlegt. Klassifikatoren mit einer hohen Genauigkeit haben einen größeren  -Score, während eine hohe Sensitivität einen höheren
-Score, während eine hohe Sensitivität einen höheren  -Score ergibt.
-Score ergibt.
(3) 
Natürlich wünscht man sich einen Klassifikator mit hoher Genauigkeit und hoher Sensitivität. Dies ist in den meisten Fällen jedoch nicht möglich. Es schleichen sich immer mal wieder Ausreißer mit ein, die selbst der beste Klassifikator nicht richtig erkennt. Die Parameter des Klassifikators müssen daher an den individuellen Einsatzzweck angepasst werden. Erhöht man beispielsweise die Genauigkeit, so leidet die Sensitivität darunter und umgekehrt. Die folgende Grafik soll dies verdeutlichen:

Rechts: Recall=0.14/Precision=0.875
Bei einer Suchmaschine beispielsweise ist es wichtig eine hohe Sensitivität (recall) zu haben, damit alle möglichen Treffer auch angezeigt werden. Sind ein paar Treffer dabei, welche falsch sind so scrollt der Benutzer einfach über sie hinweg. Anders sieht es beispielsweise bei der Exploration von neuen Bohrgebieten aus. Hier ist es wichtig, dass die Genauigkeit (precision) sehr hoch liegt und keine falschen Treffer dabei sind. Letztendlich reicht eine einzige Bohrstelle aus bei der man sicher sein kann, dass diese auch wirklich Öl liefert.