Speicher gibt es in verschiedenen Ausführungen. Je nach Anwendungsfall eignen sich bestimmte Speichertarten besser als andere. Die Komplexität und Herausforderungen an Speicherlösungen nehmen zu. Gerade im Umfeld von modernen Cloud-Lösungen ist die richtige Wahl für einen kostengünstigen und hochperformanten Speicher wichtig.
In diesem Artikel möchte ich über die Unterschiede der Speicherarten sprechen. Die Grundlagen lassen sich dabei gleichermaßen auf GCP, AWS oder eine andere Cloud-Lösung anwenden.
Das wichtigste zu Beginn ist es sich Gedanklich von der physikalischen Form der Datenspeicherung zu trennen. Während sich auf dem Heimcomputer die Daten wahrscheinlich in einer Ordnungsstruktur darstellen, welche auf einem Dateisystem beruht welches wiederum die Speicherpartitionen der Festplatte nutzt ist das ganze in der Cloud völlig irrelevant. Der Anwender benutzt die Dienste direkt. Wie diese intern die Daten abspeichern ist eher zweitrangig.
Block-Storage
Der Block-Storage speichert Daten in Blöcken ab. Die Blöcke selbst haben eine bestimmte Speichergröße und Adresse mit der diese angesprochen werden können. Müssen Daten gespeichert werden welche die Größe eines Blocks überschreiten, so müssen die Daten auf mehrere Blöcke verteilt werden. Der Block-Storage regelt dabei nicht selbst wie die Daten verwaltet werden. Er stellt nur die nötigen Speicherblöcke über ein Inteface bereit.
Eine Computerfestplatte basiert beispielsweise auf diesem Prinzip. Der Controller der Festplatte kennt weder Ordner noch Dateien. Er liest oder schreibt lediglich Datenströme welche aus adressierbaren Blöcken stammen. Das Betriebssystem des Computers ist letztendlich dafür verantwortlich diese Datenströme in eine verwaltbare Struktur zu bringen.
Auf die gleiche Weise funktioniert der Block-Storage in der Cloud. Statt dem bei der Festplatte verwendeten SCSI wird hier iSCSI verwendet. Das „internet Small Computer System Interface“ stellt dabei die gleiche Funktionalität bereit, packt die Befehle jedoch in TCP-Pakete, welche über das Netzwerk übertragen werden können.
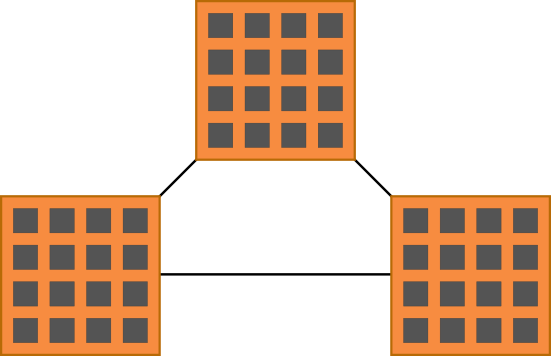
Der Vorteil gegenüber einer lokalen Speicherlösung liegt nun darin, dass die Datenblöcke nicht mehr Ortsgebunden sind. einzelne Blöcke können im Netzwerk auf verschiedene Systemen verteilt werden. Der Zugriff auf große Speicherbereiche ist daher extrem performant. Einen gewisser Nachteil ergibt sich für kleinere oder stark fragmentierte Dateien, da für jede Anfrage die Latenzzeit des Netzwerks beachtet werden muss. Moderne Glasfaser-Netzwerke sind jedoch häufig schneller als magnetische Festplattenlaufwerke mit ihrem langsamen Lesekopf.
In der Cloud werden Block-Storages meistens für Festplatten von virtuellen Maschinen eingesetzt. Festplatten können damit nicht nur von der VM entkoppelt werden, sie können auch dynamisch ihre Speichergröße anpassen. Das Hostsystem verwendet den iSCSI-Treiber wie jeden anderen Festplatten-Treiber und benötigt keine spezielle Anpassung.
File-Storage
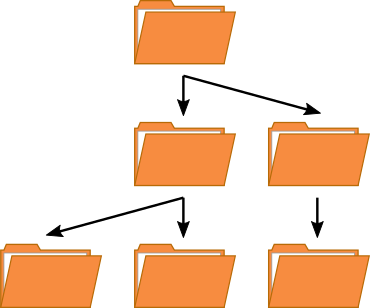
File-Storage zeichnet sich dadurch aus, dass Dateien in Ordnern strukturiert werden können. In jedem Ordner können weitere Ordner oder Dateien enthalten sein. Das ergibt eine Baumstruktur, bei dem jedes Objekt einen eindeutigen Pfad besitzt.
Dateien werden als Ganzes abgespeichert und sind durch ihren Verzeichnispfad wieder aufzurufen. Der Vorteil von Verzeichnispfaden ist ihre hierarchische Struktur. Dadurch lassen sich Dateien in Kategorien unterteilen und als Gruppe behandeln. Dadurch ist es nicht nur möglich nach unbekannten Dateien zu suchen, sondern diese mit gewissen Zugriffsrechten zu bündeln.
Ein Nachteil ergibt sich aus der steigenden Komplexität mit der Zunahme der Anzahl an Ordnern. Umso tiefer die Ordnungsstruktur reicht, umso langsamer ist zudem der Zugriff auf einzelne Dateien. Ein weiterer Nachteil ergibt sich in der beschränkten Skalierbarkeit. Zwar kann eine Hierarchie theoretisch unendlich tief gehen ein einzelner Ordner kann jedoch nur eine begrenzte Anzahl an weiteren Ordnern und Dateien aufnehmen.
In Cloud-Systemen lassen sich File-Storages dynamisch erweitern. Der Speicherbedarf kann je nach Bedarf zu- oder abnehmen. Da jeder Ordner oder jede Datei für sich selbst steht können mehrere Systeme zudem gleichzeitig unabhängige Veränderungen an deren Struktur vornehmen.
Object-Storage
Der Object-Storage stellt die einfachste Form der Datei-Verwaltung dar. Jede Datei (Objekt) wird dabei unter einem eindeutigen Namen in einer flachen Hierarchie abgelegt. Es ist somit nicht möglich zwei Dateien mit dem gleichen Namen abzuspeichern.
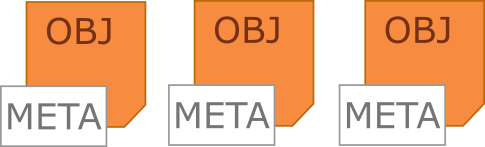
Durch die flache Hierarchie ist jedes Objekt unabhängig und kann eigenständig verwaltet werden. Ein Object-Storage lässt sich dadurch ideal skalieren. Gerade in Datenspeichern für die Cloud ist der Object-Storage daher meistens die beste Wahl.
In flachen Hierarchien geht die Übersicht über einzelne Dateien schnell verloren. Es hat sich daher als Standard etabliert Dateinamen einen Präfix wie in einer Ordnungsstruktur zu geben. Auch Dateien in AWS und GCP Buckets lassen sich so wie in einem File-Storage verwalten. Der Dateiname /home/user/test.txt sieht dann zwar aus wie eine Datei in einer Ordnerstruktur ist jedoch weiterhin nichts weiter als ein Dateiname.
Ein weiteres Feature von Object-Storages ist die Speichermöglichkeit von Metadaten. Zu jedem Objekt können eine Vielzahl von Metadaten hinterlegt werden. Diese lassen sich in Suchoperationen mit einbeziehen. Objekte können so in Kategorien unterteilt und nach ihnen gesucht werden. Es ist keine Seltenheit, dass Metadaten die Größe des eigentlichen Objektes übersteigen.
Einer der bedeutendsten Nachteile von Object-Storage liegt im bearbeiten von Objekten. Diese lassen sich nicht teilweise verändern, sondern müssen für jede Modifikation komplett neu hinterlegt werden. Eine große Datei, die häufig verändert wird sollte daher nach Möglichkeit nicht in einem Object-Storage abgelegt werden.